Pass Amazon AWS Certified Solutions Architect - Professional Certification Exam in First Attempt Guaranteed!
Get 100% Latest Exam Questions, Accurate & Verified Answers to Pass the Actual Exam!
30 Days Free Updates, Instant Download!


AWS Certified Solutions Architect - Professional SAP-C02 Premium Bundle
- Premium File 511 Questions & Answers. Last update: Apr 12, 2025
- Training Course 192 Video Lectures
- Study Guide 1066 Pages
AWS Certified Solutions Architect - Professional SAP-C02 Premium Bundle
- Premium File 511 Questions & Answers
Last update: Apr 12, 2025 - Training Course 192 Video Lectures
- Study Guide 1066 Pages
Purchase Individually

Premium File

Training Course

Study Guide




AWS Certified Solutions Architect - Professional SAP-C02 Exam - AWS Certified Solutions Architect - Professional SAP-C02
| Download Free AWS Certified Solutions Architect - Professional SAP-C02 Exam Questions |
|---|
Amazon AWS Certified Solutions Architect - Professional Certification Practice Test Questions and Answers, Amazon AWS Certified Solutions Architect - Professional Certification Exam Dumps
All Amazon AWS Certified Solutions Architect - Professional certification exam dumps, study guide, training courses are prepared by industry experts. Amazon AWS Certified Solutions Architect - Professional certification practice test questions and answers, exam dumps, study guide and training courses help candidates to study and pass hassle-free!
New Domain 2 - Design for New Solutions
33. DynamoDB - Consistency Models
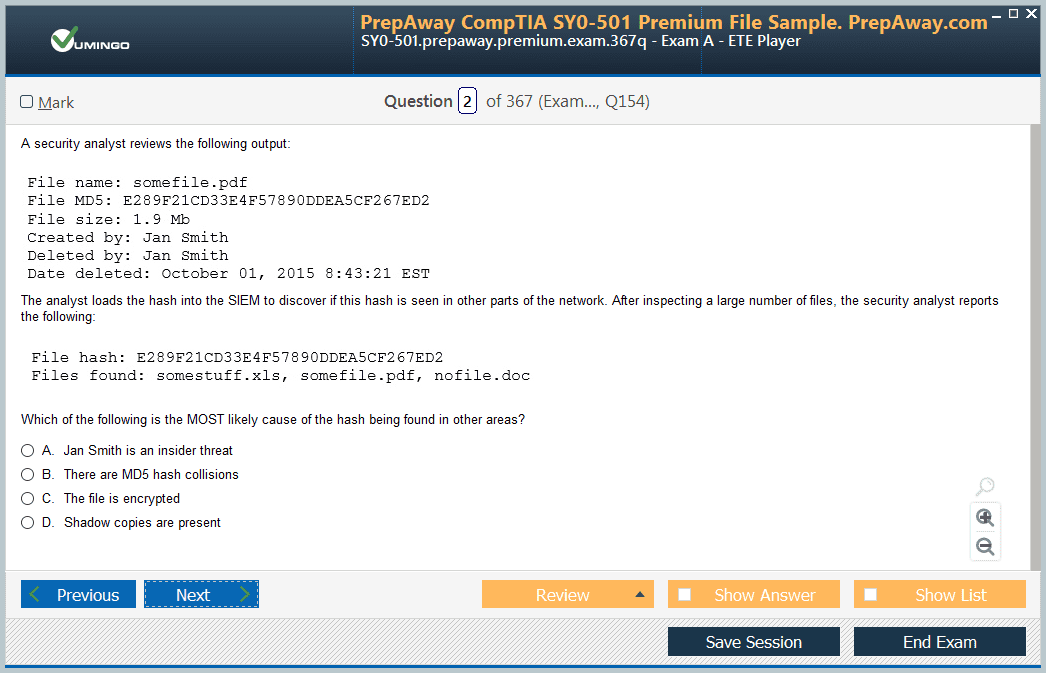
Hey, everyone, and welcome back. Now, in the earlier lecture, we discussed about the eventual consistency that one might have to face in the distributed systems. Now, going ahead, we will be speaking about the consistency model as far as DynamoDB is concerned. So let's go ahead and understand more about it. So, basically, DynamoDB is a distributed system, and it stores multiple copies of items across an AWS region to provide durability and high availability.
So, whatever we put in the DynamoDBtable, DynamoDB will copy or replicate it across multiple storage locations within an AWS region. Now, since DynamoDB is a distributed system, the challenge of eventual consistency will come here as well. So all the distributed systems will have the challenge of achieving eventual consistency. And this is the reason why DynamoDB supports two consistency models. One is the eventual consistent read, and the second is a strong, consistent read. So these are the two models that are present. So let's go ahead and understand both of them. So, in the first option, where you have eventually consistent reads, what really happens is that when we write data in the DynamoDB, it might not reflect the resulting data of a recently completed right operation.
Now, this is something that we have already seen: if you are writing some data at the first millisecond and you are trying to read it at the second millisecond, then you might not get the data back, or you might get the older data back and not the updated one. That is the definition of eventual consistency. So in order to understand more about it, what AWS has also specified is that consistency across all storage locations is reached within a second.
Now, this is very important, and this is what the DynamoDB documentation basically says: since the consistency across all storage locations is reached within a second, whenever you are writing some data to a table, make sure that you read it after 1 second. At least a 1-second gap should be there if you want to get the updated changes. So, if you try to read something in a second or less, you may be getting stale data. Now, for certain applications, this may not be acceptable. You really want things to move quite quickly. And in order to tackle this, what AWS provides is that it gives us a second model that has strong, consistent reads.
So what really happens here is that when a request is made, with the help of strong, consistent reads, DynamoDB returns a response with the most up-to-date data. So here, the eventual consistency of less than 1 second does not come into play. Now, in order to read the data with the help of strong, consistent reads, we have to specify an optional parameter in the request that we will be making. Now, this is very important, and let me show you how that would really work. So if you send a get item to the table users with a key file or JSON, what you're getting is all the attributes of this specific item. Now, since we are not specifying anything here, by default, it is an eventual consistency rate. So, if you look at the DynamoDB documentation for get item, you'll notice two optional parameters. One is a consistent read, and the other is not a consistent read.
So if I want to have a strong consistent read, this specific one, then within that request, I have to specify this specific parameter, which is a strong consistent read. So it would go something like this. Now you will get the same value, but this has performed very strong consistent read. So this is what it basically means. So if you are designing an application where you are writing the data and you want to read it within a few milliseconds itself, then the query that you will be sending to the DynamoDB backend will have an optional parameter of "consistent read." So this is one thing that is important to remember. Last but not least, nothing is free. So, if you use strong, consistent reads, it does have its own pricing. So this is one important thing to remember. So this is its ability.
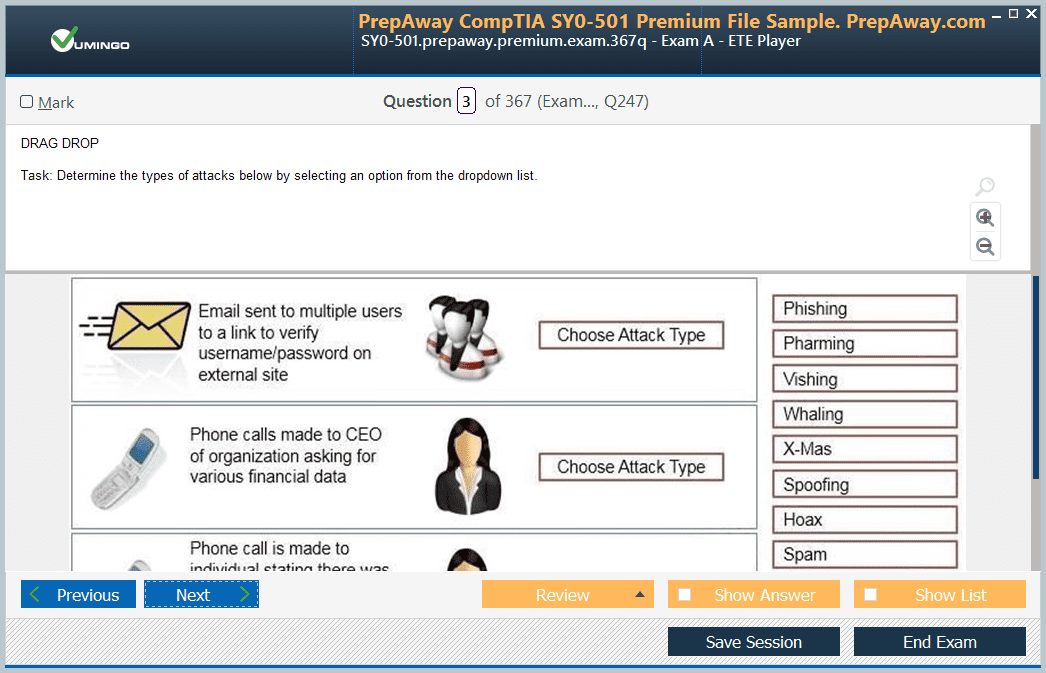
34. DynamoDB Auto-Scaling.
Hey everyone, and welcome back. In today's video, we'll go over DynamoDB autoscaling. Now, as a solutions architect, we had to specify the read capacity unit and the right capacity unit during the launch of a DynamoDB. So typically during the promotion, the solutions architect had to manually increase the RCU and the WCU; otherwise, there would be a lot of throttling of requests. So that used to be quite a pain because whenever there is a high amount of traffic, which is expected, typically a programme manager or developer would come to the DevOps scene.
He will ask to increase the read and write capacity units of the DynamoDB table. And it had to be reduced again after the promotion ended. So those things were more manual efforts there. And it is for this reason that DynamoDB auto scaling was introduced, and it has proven to be quite useful. Now, as the name suggests, DynamoDB auto scaling allows us to dynamically scale up and scale down the throughput of the DynamoDB table. Now generally, there are two ways in which you can define the throughput: the read and the right capacity units, which are also referred to as RCU and WCU. So one is based on demand, while the other is based on supply. Now, with the on-demand approach, there is no upper limit. So it's like you just create a DynamoDB table, and that's about it. If you have a lot of requests, it will automatically scale up to serve all of them.
So that proves to be quite important. So you create a DynamoDB table with OnDemand, and that's about it. You don't really need to worry about anything there. The second is provision. Provisioning is where you can enable auto-scaling and even specify the amount of RCU and WCU. Now, certain steps for DynamoDB auto scaling are generally followed. So first, this user creates a DynamoDB table. Here is the DynamoDB table. Again, if it has auto scaling, it has Cloud Watch. So Cloud Watch basically observes the overall matrix associated with the DynamoDB table. If it detects that the amount of load has increased, an SNS notification will be sent to the user informing them that it will scale. And then you have the auto-scaling part, which would update the table properties to support the higher throughput. So this is quite a straightforward approach. Now, before we continue the video, let me actually show you a few things here. So, as we're discussing, here I have a DynamoDB table, and if I click on this table, if you look into the matrix, these are the rows that are basically being observed by the Cloud Watch. So here you have the read capacity, which is the RCU, and you have the write capacity. So both of them are currently set to 5.
So this is the basic provision type, correct? This is not the on-demand type. In "on demand," you don't really set the left capacity unit and the right capacity unit. It just works perfectly without that. So let's look into both of them. So let's create a table. I'll say Kplatz and DynamoDB. All right? So, if you simply deselect the default settings in the RCU and WCU, you will see provision and On Demand. So as soon as I click on "on demand," you will see that you cannot really set the RCU and the WCU. You can even turn off the auto scaling. So one of the great ways to directly create a DynamoDB table is on demand. and that's about it. You don't have to worry about it much, apart from the cost perspective. So the second one is the provision. Again, in provision, you can set the read capacity unit and the write capacity unit, and you can even set the auto scaling related aspect if you need to. So here you can manually specify what the RCU and the WCU are. You can even go ahead and set the auto-scaling parameters accordingly.
Now, one of the questions that would typically come up is, "Hey, on demand seems to be quite good." Why won't I just choose "on demand" instead of going through the auto scaling process and specifying the provision capacity? Because even if you use auto scaling, you have to specify various things like target utilisation, provision capacity, maximum provision capacity, and all in terms of on demand. It just works out of the box. Now, the reason for not choosing on demand is the pricing aspect. So generally, when the on-demand option was released, it was like five to six times more expensive than the provisioned option here. All right? So it all comes down to the cost. You can go ahead and select if you use provision. So this is something that falls to you, but you will get it for a lot less money. On demand is certainly quite expensive compared to provision, but you will not really have late-night alerts.
35. DynamoDB Global Tables
Hey everyone, and welcome back. In today's video, we will be discussing the DynamoDB global tables. Now, a global table is basically a collection of one or more replica tables that are all owned by a single AWS account. Now, this can be explained with the following diagram, where you have a table zero in region one and a table one in region two. Now, there is a replication that is occurring between both of these tables, and AWS takes care of the replication. One great thing about this is its high availability. Assume that if region one goes down and the DynamoDB is unavailable, you can redirect all traffic from your application to the region's DynamoDB table as well, and all data will be stored. Now, this type of architecture is typically used by big organisations that receive traffic from all around the world. Netflix is one such example.
They have a customer base across the world. Now, if they only have a DynamoDB table in North Virginia, the number of latencies will increase. So having the table in multiple regions not only helps with high availability but also decreases the overall latency. Now one important part to remember is that each of the replicas stores the same set of data items. You cannot have a partial replication in this type of architecture. So let's go ahead and build this practically.
So I'm in my DynamoDB console. Let's go ahead and create a table. Let's call this category "video courses." Let's say the primary key is instructor, and we can add a sort key that is "video course name." All right, we can go ahead and create a table. So let's just quickly wait for the table to be created. Great. So our table is now complete. Let me just maximise this. There is now a Global Tables tab within this section. Just click here, and we need to first enable the streams. So let's enable the stream. I'll just select the default view type, and I'll click on Enable. Great.
So once your stream is enabled, the next thing that you need to do is add a region. So within the region, you can select the region where you want your replica copy to be in. Let me select Singapore. You can also proceed by clicking "Continue." So now what DynamoDB will do is create a table in Singapore. So first, it will check whether any tables with the same name exist in Singapore or not. If not, then it will go ahead and create a table in Singapore with the same name. And then the replication would be initiated. So let me click on "Go to Table." This will take me to the Singapore region. You can also see the table being created here. So in order to verify whether the replication is working as expected or not, let's create a new item. So for the instructor, I'll just put it as "Z" and the video course name. I'll say AWS. Let's go ahead and do a save. So, this is the new entry that we have created in the North Virginia region. Now, if you look into the Singapore region, you have the same entry. Let me just click here.
You've got the instructors and the title of the video course. Now, do notice that AWS also adds certain data, which is AWS rep deleting, AWS rep update region, and AWS rep update time update region, which is basically which region it was updated. And this is the updated time. So this is something that DynamoDB adds. So make sure you do not delete this. So, coming back, we have the concept of default attributes. Now, default attributes So basically, whenever you are using a global table, then DynamoDB will add a certain set of default attributes for all the items that you are adding to the table to keep the table in sync. Now, these are the default attributes. The first is AWS rep deletion, followed by AWS rep update time and AWS rep update region. Now, as we already discussed, you should not alter these attributes or create any new attributes with the same name. This is very important to understand.
Now, coming back to some of the important points that you need to remember The first is that in a global table, a newly written item is usually propagated to all the replica tables within seconds. So this is something that we have already seen. The second important point that we also discuss is that within a global table, each replica table stores the same set of items. And DynamoDB does not support partial replication for only some items. So partial replication is not supported. Now, it might happen that a specific set of applications is writing at the same time to two different DynamoDBs, which can result in a conflict. So, when there is a conflict, the last writer wins. As a result, any item that was last written will be added to the prior.
36. DynamoDB Accelerator (DAX)
Hey, everyone, and welcome back. In today's video, we will be speaking about the DynamoDB accelerator. So DAX is a relatively new service provided by DynamoDB, and it has enormous potential, particularly during workloads that involve a significant amount of reading. So just the two revised DynamoDB accelerators, which are also referred to as DAX, are fully managed, clustered in memory caches for DynamoDB.
So it is very similar to what you can refer to as memcache or redis when it comes to relational database terminologies. So one of the great things about DAX is that it can deliver up to a ten-fold improvement in performance improvement. So DynamoDB is quite fast when dealing with millisecond-level transactions, but in the next generation workload, where you want to reach the microsecond level, the DAX is critical. So how DAX really works is that you have your application, and within your application, you refer it to the DAX client.
So your application is directly referring to the DAX client. Now, the DAX client is basically the end point to the DAX cluster that is created, and that DAX cluster, in the back end, connects to DynamoDB. So basically, what really happens is that this cluster stores a lot of cash. And typically during the workload, where you have a huge amount of feed, it might happen that the same item is being queried by thousands of clients, and that item can be cached over here. And next time, when a client requests it, the data would come from the cache and not from the DynamoDB. And because this cache is in memory, you would see a significant performance boost. So let me quickly show you what exactly it might look like. So, as you can see, I have a DAC over here in my DynamoDB. And within the DAX, if I go to the dashboard, you have to create a cluster. So this is the DAX cluster that I am referring to.
So within this cluster, you can have a note type and a cluster size. You also have options for encryption. And this is what will basically create a cluster. Now, once the cluster is created, you will have an endpoint URL that you will have to integrate with your application. So let me quickly show you how this specific block really lookslike, let me quickly show you. So this is the sample Java code that I have over here. And basically, if you see over here, I am calling a DynamoDB client over here. So this is where I am calling a DynamoDB client. So this is the code where DAX is not used. Now, let's assume that you already have Java code that is written to integrate with DynamoDB. And tomorrow, you want to make it work with the DAX.
Also, it is quite simple. So in this specific area, you replace it with your DAX client code. So this is where you are referring to the DAX client code. And if you'll see over here, you are actually specifying the host name of the cluster. So basically, this is the DNS name of the cluster along with the port. So what you're doing is, within your code, you're referring to the DAX client, where you're putting the endpoint URL of this DAX cluster. So next time when your code tries to query, it will send a request to the DAX cluster, and if the data is not present, the DAX cluster will make a request to the DynamoDB. If the data is present, then it will directly send it from the cache. So this is how the basic DAX really works.
Because a DAX is more of a caching type of functionality, you must remember which areas DAX is suitable for and which areas DAX is not suitable for. So where DAX is not suitable, it is not suitable for workloads where strong, consistent reads are required. Keep in mind that because you're saving from the cache or certain queries made by your Dash client can come from the cache, it's possible that it won't be a strong, consistent read.
The second type of application involves massive amounts of data. Because if you have a huge amount of writing, there is one more layer that is added. And this is the reason why, if your application is doing most things right, having an additional layer here does not really make sense and would add up to a transaction cost. Again, applications that do not perform a large number of read operations are not recommended. And again, applications that do not require a microsecond-level response time DAX is not really a choice because you have to spend money for a DAX cluster.
And, if you're satisfied with DynamoDB Pro's millisecond level-transaction response time, there's no need to incur additional costs here. So if you don't really need a microsecond-level response time, just avoid adding complexity and cost. So, just remember certain important points for the exams. That is basically an in-memory caching system.
So all of this cache is always stored in memory; it is never stored on disk. Now it improves the response time for eventual consistency in workloads. Remember that it is not suitable for the workload, which requires strong, consistent reading. That is where it is not suitable; it is really suitable for an eventual consistent read. Now, the third important point is that we need to have a client that basically points to the DAX instead of DynamoDB. This is something that we already saw in the code, where we are pointing it to the DAX cluster. The final point for the DC exam is that tax is not really appropriate for workloads this intense.
AWS Certified Solutions Architect - Professional certification practice test questions and answers, training course, study guide are uploaded in ETE files format by real users. Study and pass Amazon AWS Certified Solutions Architect - Professional certification exam dumps & practice test questions and answers are the best available resource to help students pass at the first attempt.



